Forum Replies Created
-
AuthorPosts
-
 Suman M.Keymaster
Suman M.KeymasterWhile selecting the items using Scraper you’ll see either blue or green highlight color. For the links you’ll see green highlight color so that it’ll help to show that the links are selected. It is helpful during Multiple Post fetch to select the link.
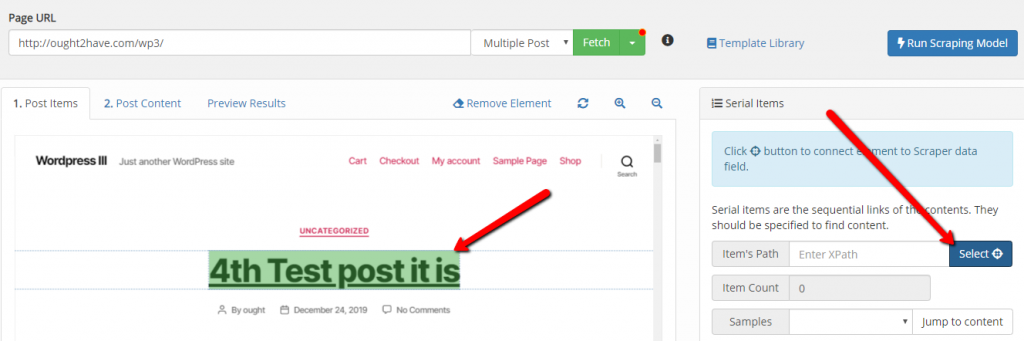
If links are not selected then highlight color will be blue.
Attachments:
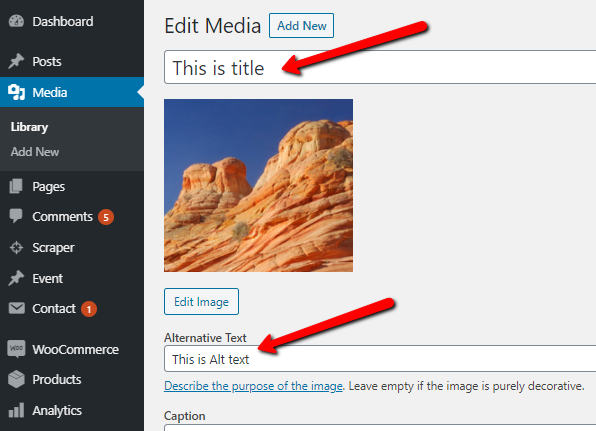
You must be logged in to view attached files.Suman M.KeymasterYou can assign Alt and Title tags to the featured image. For this you’ll need to enable/check the options “Alt” and/or “Title”. Scraper will then fetch Alt and Title tags from the selected image if they are available.
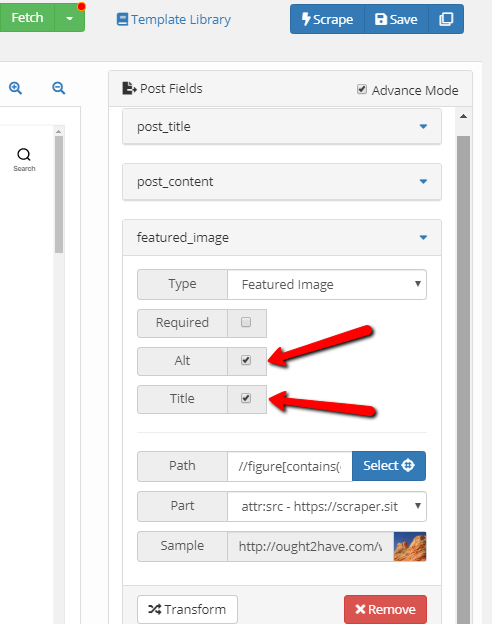
Alt and Title tags assigned to downloaded image via Scraper.
Attachments:
You must be logged in to view attached files.Suman M.KeymasterUsing Scraper PRO you can now scrape from AJAX based websites and AJAX content within the website. Scraper Pro is our headless browser which enables AJAX functionality for dynamic sites. We’ve launched our new service – “Scraper Ajax Service” for $9/mo. Its paid, because we have to launch a series of specialized servers to headless browser fetching. This enables our users to crawl websites which are built with dynamic background loading or in short AJAX.
More info here.
How to enable Scraper Ajax Service?
- Click on dropdown icon besides ‘Fetch’ button and click on ‘Scraper Pro’ menu item.
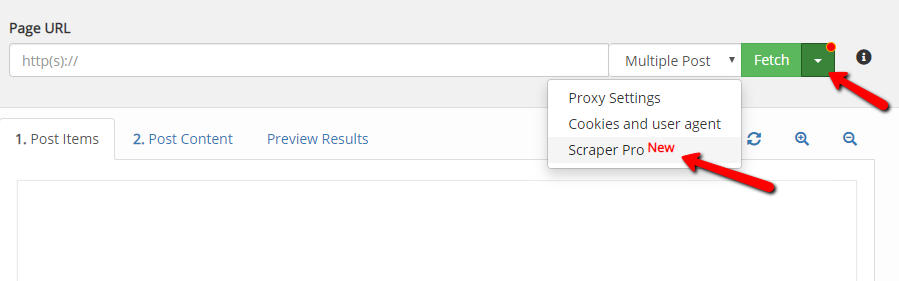
2. Subscribe to Scraper Pro.
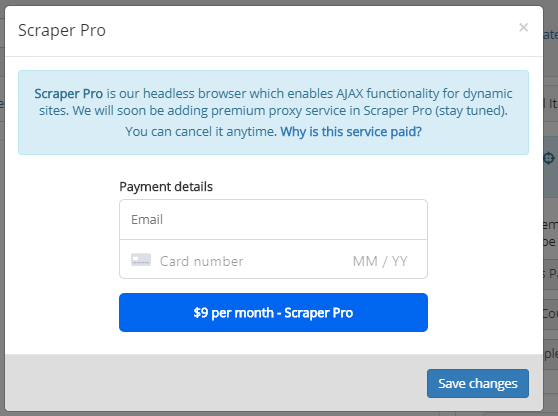
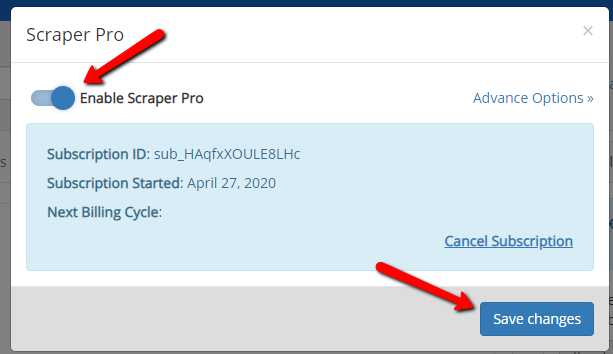
3. After subscribing, you can enable Scraper Pro.
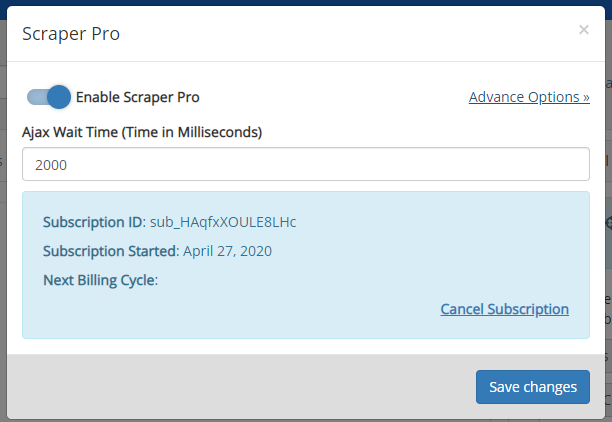
4. In some case you might need to increase Ajax wait time so that the Ajax content from the site is fetched.
Attachments:
You must be logged in to view attached files.Suman M.Keymaster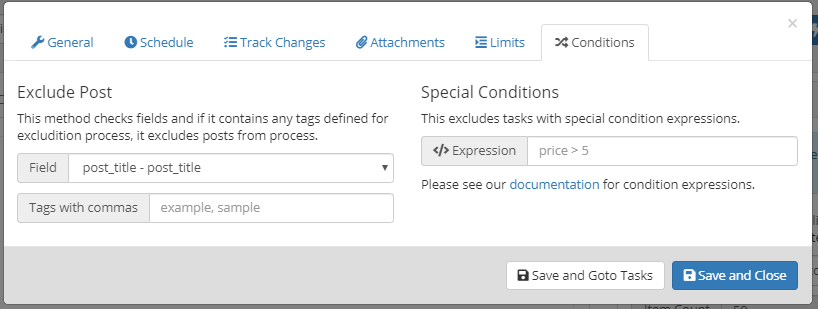
If you want to exclude items/posts with specific tags/words then you can use ‘Exclude Post’ feature.
Please check this for ‘Special Conditions’ feature
Suman M.Keymaster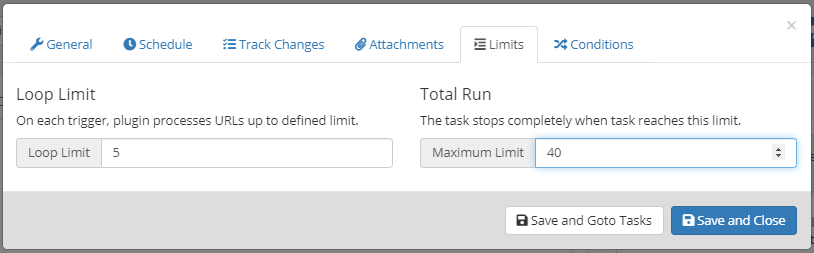
In this section, you can define how many items to process in each trigger. It’s recommended to use this option if there are several items to be imported. For example, you can set ‘Loop Limit’ to 5, which means 5 items will be processed in each loop.
If you set a value for ‘Total Run’ then only than many items will be imported at max.
Suman M.Keymaster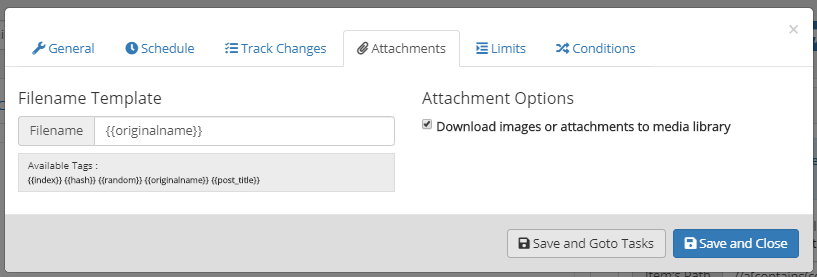
Here you can define if you want to download the images (e.g. Featured Image) to media library or not. You can also define the filename for the attachments.
Suman M.Keymaster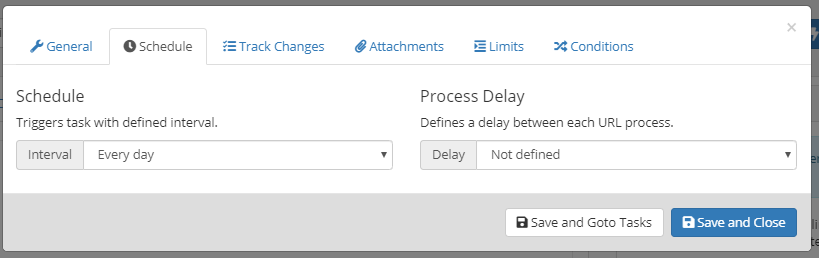
Here you can select when the task shall run. This will basically schedule the task to run at defined interval.
Please also check this.
Suman M.Keymaster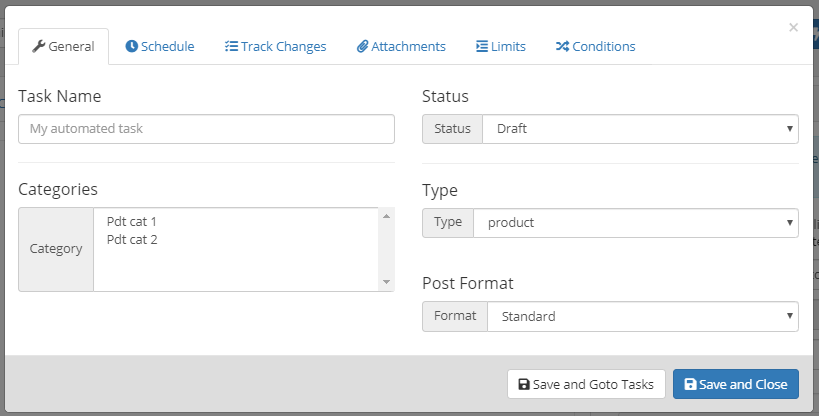
In this section, you can
- enter the name for the task
- select categories for the items imported/scraped
- assign status for imported items/posts
- select the post type for the scraped content (whether you want it to be imported as post, product, custom post type, etc.)
Suman M.KeymasterIn Chrome browser there is a tool called “Inspector”. With this tool, you could get hidden values and use their xpath addresses on Scraper tool.
- To open this tool, please go to URL on your Chrome browser. And right-click on element that you want to scrape.
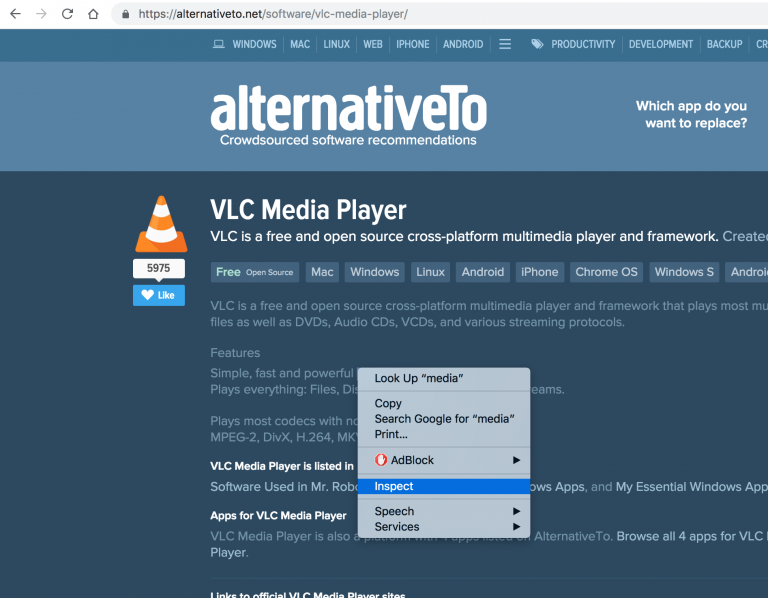
2. Click “Inspect” button to open “Inspector” tool.
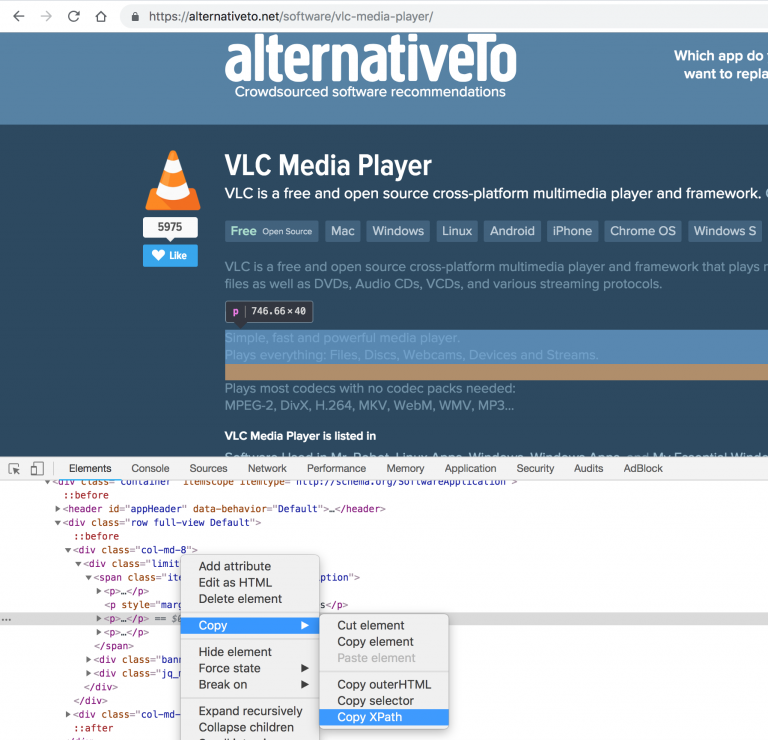
There will open a menu with element list. System will automatically select element and show it to you with blue area. Right-click on element and click on “Copy XPath” action in Copy menu.
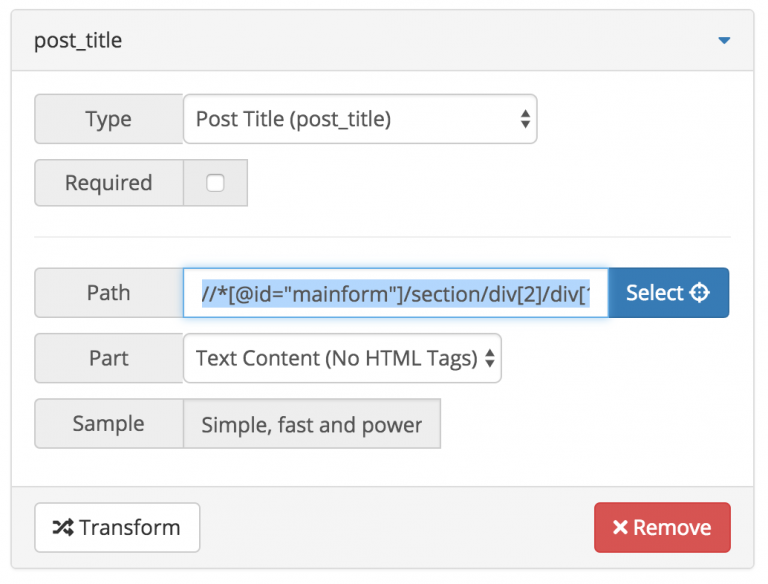
This copied value can be used on Scraper tool easily. Even element is hidden plugin is able to get this value.
Please note that some websites provides these values with ajax services. In this case, you won’t see the value in Sample field. That means plugin is unable to get this value.
Attachments:
You must be logged in to view attached files.Suman M.KeymasterTo enable translation on Scraper, please go to “Licence and settings” menu. There are different fields for different services. Scraper currently supports Google Translation, Yandex Translate and DeepL translation services.
Enter your license key and click “Save Changes” button.
Scraper supports partial translation. Meaning that, you could only translate one part of your post. For example, you could only translate post title or only post content with partial translation support. That can be useful for some cases where you need to translate only a custom field.
To enable translation on a post, please click “Transform” button for the field that you want to be translated. There is a section called “Translations”. Go to translations section and choose the language from list.
The field you’ve set will be translated the language you select. Please note that you should also set post title, post content and other fields (if there is any) to translate a post fully.
Suman M.KeymasterIn Scraper you could exclude posts by checking some parts of post. This feature prevents duplicates on post processes.
There are three different types for uniqueness check method :
- Post title
- Post URL
- Product SKU Code
Plugin sets these variables on each process for every post and checks on processes, if these values are matching with current process. If they has same values, it excludes and doesn’t create post.
You could enable uniqueness on Project settings > Track changes section.
Suman M.KeymasterIt’s possible to download any PDF attachment to your website. Please follow the introductions below:
- Create new data field.
- Select “Download File” from type list.
- Select the link of attachment with visual selector.
- Select “attr:href” from attribute part list.
- Rename your variable on “shortcode” field.
The plugin will download pdf and provide you the link of attachment with shortcode you’ve defined. You could use this shortcode on your post content or any custom field.
If you want to rename your PDF files, you could use file name template option on project settings.
Please make sure that the source provides the PDF URL without any authentication.
Suman M.KeymasterOn visual editor, there is an option to remove useless elements from page.

On the right side, there is a button for removing elements. You could click on that and click on element to remove any popup, dropdown website.
Attachments:
You must be logged in to view attached files.Suman M.KeymasterIn some cases, the source site may block you. In that case, you may use proxy and continue to scraping. To check connectivity to source site please follow instructions below :
- Create a sample task with “single-post” option.
- As a post title, select any title from website, you could write //h1 on path for example.
- Trigger this task to create new post on your website.
- If it creates a task with the title you want, there shouldn’t be any connection issue.
You could also see errors when you trigger task. Please enable reporting on settings page to see detailed logs.
If there is a connection issue to source site, you could simply define proxy and continue scraping.
December 31, 2019 at 7:33 am in reply to: Troubleshoot : It clears HTML content after scraping #1161Suman M.KeymasterIn Scraper, there are too much features to transform data for your needs. In some cases, that causes conflict and it ends up with issues.
One of the most common problems on scraping HTML sanitize function problem. On transform function, we have an option to clear source content for HTML tags. It can be easily (and automatically most of time) enabled for post_content.
But in some cases you use HTML elements for your content, it also clears HTML content as well. If you have an iframe on your content and this field also clears HTML tags, that means your iframe elements won’t show up after scraping.
To solve this issue, you should create a variable for your content and use it on your post_content field. Enabling HTML clean function for variable and disabling clean function for post_content solves this problem.
In this video, we created a separate variable for our content and use it on post_content field to fix transform function conflicts. This is the same issue for HTML clear function and both of this methods can be solved with this way.
-
AuthorPosts